
【更新ing】从零开始的LeetCode每日一题
每日算法
计划寒假期间至少保证每天一道新题,随时复习之前未AC的旧题
标*的题目是第一次没有AC,看了答案的,后面需要多次巩固
博客灵感来源:LeetCode每日一题(新) | HillZhang的博客 (gitee.io)
2024.1
9. 回文数(Easy)
题目描述
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。例如,121 是回文,而 123 不是。
示例 1:
1 | 输入:x = 121 |
示例 2:
1 | 输入:x = -121 |
题解
法1:双指针法
非常蠢笨易想的一种方法,看到这道题脑子第一反应就是这个,同时考虑到负数不可能是回文数,所以直接对所有负数返回false;
1 | class Solution { |
法2:反转一半数字
将数字本身反转,将反转后的数字和原始数字进行比较,若相同则该数字回文,同时为避免数字反转可能导致的溢出问题,只考虑反转int的一半(毕竟回文数后半段反转后应该与前半段相同)
1 | class Solution { |
2024.3
不要问为什么隔了这么久……
142.环形列表②(Medium)
题目描述
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
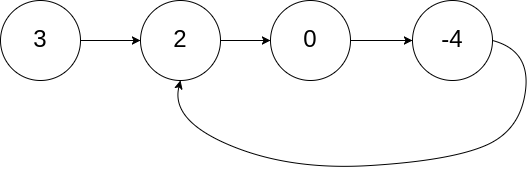
1 | 输入:head = [3,2,0,-4], pos = 1 |
题解
对于链表找环路问题,有一个通用的解法——Floyd判圈法
Floyd判圈法
快指针和慢指针以1:2的速度前进。
当快指针再次与慢指针相遇时,它们行进路程的差值一定为圈长的整数倍。
设进入圈前的链长为m,圈长为L,慢指针走了a圈,快指针走了b圈,它们第一次相遇在距离入圈点d的位置,则
$$S = m + a*L + d $$
$$2S = m + b*L + d$$
解得 $m = (a-2b)*L-d$
考虑模拟上述过程,在两个指针再次相遇时停下来。
此时将慢指针移动至初始结点,快指针不动,以$1:1$的速度继续前进。
思考一下,由于两指针此时速度相同,若是能相遇,则相遇点只能为入圈点,那么根据行进路程可得以下等式
$$m = n*L - d$$
将m代入得 $(a-2b)L = nL$ 一定成立。
1 | /** |
76.最小覆盖子串(Hard)
题目描述
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:
- 对于
t中重复字符,我们寻找的子字符串中该字符数量必须不少于t中该字符数量。 - 如果
s中存在这样的子串,我们保证它是唯一的答案。
1 | 输入:s = "ADOBECODEBANC", t = "ABC" |
进阶要求:时间复杂度不超过$O(n)$
题解
本题使用滑动窗口求解,两个指针均从左向右移动,且l永远在r的左边或重合。
1 | class Solution { |
一点++和–的小技巧:
a++和++a均是将a+1,但a++返回值为a,++a的返回值为a+1.如果只是希望增加a的值,而不需要返回值,推荐使用++a,运行速度略快一些。
633. 平方数之和(Medium)
题目描述
给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得
$$ a^2 + b^2 = c $$
1 | 输入:c = 5 |
题解
法1:暴力遍历
这道题其实非常基础,无非是使用双指针前后移动寻找合适的解,主要问题在于如何降低时间复杂度。根据题目可以知道c的取值最大为2^31。若是l指针从左至右,r指针从右至左,不难想到溢出问题。既然是求平方和,a和b的大小不可能大于c的平方,因此r指针可以从根号c开始遍历。考虑一下极端情况,例如c的值为2147482647时,平方和相加一旦大于c,int就会溢出,所以可以将指针和sum的数据类型定义为long。
1 | class Solution { |
法2:数学思维
根据前几个数 1 = 0 + 1;4 = 1 + 3; 9 = 4 +5;16 = 9+7;
不难看出,所有平方数都可以化作一个奇数与前一个平方数的和。因此可以将c每次减少一个奇数,判断剩下的数是否为平方数。由于等差数列
$$ 1 + 3 + 5 + 7 +… +2n-1 = n^2 $$
减去的数之和也为平方数。
1 | class Solution { |
680.验证回文串②(Easy)
题目描述
给你一个字符串 s,最多 可以从中删除一个字符。
请你判断 s 是否能成为回文字符串:如果能,返回 true ;否则,返回 false 。
1 | 输入:s = "aba" |
题解
利用双指针从两头遍历字符串,判断是否是回文串,若不是回文串,则尝试删除一个字符(即查看下一个字符是否与另一边相同),由于只能删除一个,所以添加一个flag属性标记是否有过修改……思路没毛病,但似乎忽略了一些东西。
根据上面的内容写出代码如下
1 | class Solution { |
很显然,上述代码先查看右边的行不行再看左边的,仅仅检验了一位,删除后会继续遍历,这样得出的结果仅是局部最优解,很容易就被套路住了(
例如第460多个测试用例"lcupuufxooxfuupucul" "bececabbacecb”
因此,我们无法通过仅判断相邻字符确定删除哪一边的字符,就只好将两种删除情况分别遍历,最后取或运算即可。所幸只能删除一个元素,最多只需要遍历两个字符串,并不会增加太多负担。修改后代码如下
1 | class Solution { |
524.通过删除字母匹配到字符串(Medium)
题目描述
给你一个字符串 s 和一个字符串数组 dictionary ,找出并返回 dictionary 中最长的字符串,该字符串可以通过删除 s 中的某些字符得到。
如果答案不止一个,返回长度最长且字母序最小的字符串。如果答案不存在,则返回空字符串。
1 | 输入:s = "abpcplea", dictionary = ["ale","apple","monkey","plea"] |
题解
首先分析题目,我们需要确定dictionary数组中的字符串是否为s的子串,这个验证可以采用双指针进行匹配,定义两个指针m和n,分别指向s和dictionary中某一个字符串的首位字符,m指针依次向右遍历s字符串,若遇到相同字符,则n指针向右移动。直至到达字符串尾。此时若目标子串遍历完成,即确定它是s的子串,则需要考虑是否为最优解。通过定义max_s属性记录当前最优解。由于题目要求返回长度最长且字母序最小的字符串,则可以在进入双指针匹配前就将长度短于目前最优解的字符串排除。因此只需考虑更长的和长度相等但字母序不同的字符串。
长度更长,毫无疑问是更优解,需要更新max_s;若长度相等但字母序更小,也需要更新max_s。最后将max_s返回即可。
代码如下
1 | class Solution { |
2024.4
69. x的平方根(Easy)
题目描述
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
1 | 输入:x = 8 |
题解
起初:这不轻轻松松简简单单
程序:超时超时超时
由于题目限制x为非负整数,我们可以知道在[0,x]区间内一定能找到一个符合要求的算术平方根。将0的情况单独考虑,在区间[1,x]内进行二分查找,使用闭区间的写法即可。
1 | class Solution { |
法2:牛顿迭代法
公式为
$$ x_{n+1} = x_n - f(x_n)/f’(x_n)$$
其中给定
$$ f(x) = x^2 - a = 0 $$
可算出迭代公式为
$$ x_{n+1} = (x_n + a/x_n)/2 $$
1 | class Solution { |
34.在排序数组中查找元素的第一个和最后一个位置(Medium)
题目描述
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例 :
1 | 输入:nums = [5,7,7,8,8,10], target = 8 |
题解
最直接的思路肯定是使用双指针从前往后遍历一便,找到目标元素第一次和最后一次出现的坐标,但这样的时间复杂度为O(n) ,不符合题目的要求,且没有用到有序数组的条件。
由于题目要求时间复杂度为 O(log n) ,此题需使用二分查找的方法,加上是有序数组,可以轻易地拥有查找思路,但是该怎么准确地分辨出起始和终止的位置呢。最终代码如下
1 | class Solution { |
由于对区间知识的不熟悉,很明显这是一种有点混乱的写法(
看到了一个思路,左侧查找第一个等于target的值,右侧查找值为第一个大于target的位置-1,这样的话显然比上面那个合理多了(,只需要修改searchRightRange函数,以及end的赋值,改后如下
1 | class Solution { |
81.搜索旋转排序数组②(Medium)
题目描述
已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转 ,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,4,4,5,6,6,7] 在下标 5 处经旋转后可能变为 [4,5,6,6,7,0,1,2,4,4] 。
给你 旋转后 的数组 nums 和一个整数 target ,请你编写一个函数来判断给定的目标值是否存在于数组中。如果 nums 中存在这个目标值 target ,则返回 true ,否则返回 false 。
你必须尽可能减少整个操作步骤。
来点讨厌的示例
1 | 输入:[1,1,1,1,1,1,1,1,1,13,1,1,1,1,1,1,1,1,1,1,1,1] 13 |
题解
由于本人正在做二分查找的系列题,所以这道题毫不犹豫进行二分。由于是一个旋转后的数组,是部分顺序排列的,所以可以通过和区间起始点或结束点的比较来判断这部分是否为有序,否则另一部分有序。为了方便,我们可以先进入有序区间进行查找,若该区间没有目标值,则继续二分查找另一区间。
同时,由于每个数字并不唯一,可能出现无法判断是否有序的情况,例如若起始点与区间中点的值相同,则无法断言左区间是否有序,此时可将起始点+1,继续查找新区间的中点,直到可以判断是否有序为止。
1 | class Solution { |
153.寻找数组最小值(Medium)
题目描述
已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次旋转后,得到输入数组。例如,原数组
1 | nums = [0,1,2,4,5,6,7] |
- 若旋转
4次,则可以得到[4,5,6,7,0,1,2] - 若旋转
7次,则可以得到[0,1,2,4,5,6,7]
注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
题解
根据旋转的定义,我们可以判断出,在旋转后的数组中,最小值左侧数组是有序的,最小值右侧也是有序的,并且右侧的值恒比左侧小。在二分查找时,我们可以将数据大小进行比较。若区间右侧nums[r]大于区间中点nums[mid] ,则可以确定最小值min不可能出现在mid右侧,下一次查找不必考虑右侧的数据;若区间右侧nums[r] 小于区间中点nums[mid] ,则最小值min出现在mid右侧,此时不必考虑左侧的数据,以此查找,直到只剩一个数为止。
1 | class Solution { |
154.寻找旋转排序数组的最小值②(Hard)
题目描述
已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次旋转后,,得到输入数组。例如,原数组
1 | nums = [0,1,4,4,5,6,7] |
在变化后可能得到:
- 若旋转
4次,则可以得到[4,5,6,7,0,1,4] - 若旋转
7次,则可以得到[0,1,4,4,5,6,7]
注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个可能存在 重复 元素值的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
你必须尽可能减少整个过程的操作步骤。
题解
这道题是153题的进阶版,区别在于数组中含重复元素,整体思路大致相同,只需要多考虑重复的情况,由于重复元素并不会影响对于最小值的判断,此时可以将区间进行移动,剔除掉重复元素。
1 | class Solution { |
单例模式 小明的购物车
事实证明这已经不再是一个只有leetcode的记录了……
题目描述
小明去了一家大型商场,拿到了一个购物车,并开始购物。请你设计一个购物车管理器,记录商品添加到购物车的信息(商品名称和购买数量),并在购买结束后打印出商品清单。(在整个购物过程中,小明只有一个购物车实例存在)。
输入包含若干行,每行包含两部分信息,分别是商品名称和购买数量。商品名称和购买数量之间用空格隔开。
输出包含小明购物车中的所有商品及其购买数量。每行输出一种商品的信息,格式为 “商品名称 购买数量”。
输入示例
1 | Apple 3 |
输出示例
1 | Apple 3 |
题解
简单起见,这里选用饿汉模式,即实例在类加载时就被创建,单例模式为了防止外部实例化,需要设置私有的构造方法,由于本题需要将商品名与数量同时存储且一一对应,故而选择Map进行存储。
1 | import java.util.LinkedHashMap; |
*4.寻找两个正序数组的中位数(Hard)
题目描述
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
示例
1 | 输入:nums1 = [1,3], nums2 = [2] |
题解
法1:寻找第k小
如果不考虑时间复杂度,这道题就简单得多了,比如说可以先将俩数组合并,取合并后数组的中位数,只可惜这样做的时间复杂度和空间复杂度均是O(m+n)。为了达到log级的复杂度,我们需要进行二分查找,此处一个十分巧妙的思路就是将寻找中位数转化为寻找第k小数,利用寻找第k小数的算法进行。
此处我们进行循环,每次循环排除前k/2个数字,即比较两个数组的第k/2个数字,排除掉较小的那部分,之后更新k值继续循环,此处k即为距离中位数还需要排除的数字个数。
此处有一种特殊情况,比如说两个数组[1],[2,3,4,5,6,7],很明显第一个数组小于第二个数组,k=4,我们需要排除掉2个数字,但是第一个数组长度为1。为了防止越界,我们在排除前先比较k/2和当前数组的长度,取较小者进行排除。
若是排除后有一个数组为空了呢?为了减少比较次数,我们在每次递归的开始,便比较两个数组的长度,将较短的数组置于nums1的位置,这样即使有数组为空,我们也能肯定是第一个数组。此时仅需要在nums2中找到第k个位置返回即可。
1 | class Solution { |
法2:轮切(误)
时间复杂度更低,但水平不够没看明白,等弄明白了再补
工厂方法模式 积木工厂
题目描述
小明家有两个工厂,一个用于生产圆形积木,一个用于生产方形积木,请你帮他设计一个积木工厂系统,记录积木生产的信息。
输入描述
输入的第一行是一个整数 N(1 ≤ N ≤ 100),表示生产的次数。
接下来的 N 行,每行输入一个字符串和一个整数,字符串表示积木的类型。积木类型分为 “Circle” 和 “Square” 两种。整数表示该积木生产的数量
输出描述
对于每个积木,输出一行字符串表示该积木的信息。
输入示例
1 | 3 |
输出示例
1 | Circle Block |
通过代码
1 | import java.util.ArrayList; |
抽象工厂模式 家具工厂
题目描述
小明家新开了两个工厂用来生产家具,一个生产现代风格的沙发和椅子,一个生产古典风格的沙发和椅子,现在工厂收到了一笔订单,请你帮他设计一个系统,描述订单需要生产家具的信息。
输入描述
输入的第一行是一个整数 N(1 ≤ N ≤ 100),表示订单的数量。
接下来的 N 行,每行输入一个字符串,字符串表示家具的类型。家具类型分为 “modern” 和 “classical” 两种。
输出描述
对于每笔订单,输出字符串表示该订单需要生产家具的信息。
modern订单会输出下面两行字符串
modern chair
modern sofa
classical订单会输出下面两行字符串
classical chair
classical soft
输入示例
1 | 3 |
输出示例
1 | modern chair |
代码
1 | import java.util.Scanner; |
2024.5
347. 前K个高频元素(Medium)
题目描述
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
1 | 输入:nums = [1,1,1,2,2,3],k = 2 |
题解
由于需要统计单个元素的出现频率,可以采用桶排序来降低时间复杂度,首先需要遍历整个数组,统计所有元素及其出现频率,然后按照出现频率进行排列,选出最高的k位元素进行输出。由于数组中元素未知,采用字典较为合适,如map等,此处介绍一个基于哈希表实现的时间复杂度更低的数据类型
unordered_map
unordered_map和map类似,都是存储的key-value的值,可以通过key快速索引到value。不同的是unordered_map不会根据key的大小进行排序,存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的。unordered_map的底层是一个防冗余的哈希表(开链法避免地址冲突)。unordered_map的key需要定义hash_value函数并且重载operator ==。
哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,时间复杂度为O(1);而代价仅仅是消耗比较多的内存。哈希表的查询时间虽然是O(1),但是并不是unordered_map查询时间一定比map短,因为实际情况中还要考虑到数据量,而且unordered_map的hash函数的构造速度也没那么快,所以不能一概而论,应该具体情况具体分析。
1 | class Solution { |
215.数组中的第K个最大元素(Medium)
题目描述
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
题解
看到这个题目,很明显需要排序,该如何选择排序方式呢?我们可以选用内置的sort方法进行排序,然后返回数组的第nums.size()-k位即可,但是这个方法的时间复杂度为O(nlogn),不符合题目中要求的O(n)。
题目要求返回第k大的数字即可,不需要将整个数组进行排序,根据快速排序原理,若某次划分后,基准数的索引刚好是n-k的话,意味着它就是我们要找的数字,此时可以直接将其返回,无需继续排列。
1 | class Solution { |
然而,若是考虑极端情况,若每次划分均将数组分为1和n-1,且第k大数每次都在n-1中,这种情况下快排的时间复杂度为O(N^2)。卡在了最后一个测试用例,在提交记录上看不完全,怀疑有特别长,最后超时
1 | [2,3,4,5,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1] |
观察这个用例不难发现,重复的元素特别多,而上述代码将重复元素等同于小于,所以会在上面做许多无用功,一种解决方案是使用三路划分,每轮将数组依照基准数划分为三个部分:小于、等于和大于。这样当发现第k大数处于等于基准数的子数组中时,可以直接返回该元素
为了提升算法的稳健型,这里采用随机选择的方式选定基准数
1 | class Solution { |
原型模式 矩形原型
题目描述
公司正在开发一个图形设计软件,其中有一个常用的图形元素是矩形。设计师在工作时可能需要频繁地创建相似的矩形,而这些矩形的基本属性是相同的(颜色、宽度、高度),为了提高设计师的工作效率,请你使用原型模式设计一个矩形对象的原型。使用该原型可以快速克隆生成新的矩形对象。
输入描述
首先输入一个字符串,表示矩形的基本属性信息,包括颜色、长度和宽度,用空格分隔,例如 “Red 10 5”。
然后输入一个整数 N(1 ≤ N ≤ 100),表示使用原型创建的矩形数量。
输出描述
对于每个矩形,输出一行字符串表示矩形的详细信息,如 “Color: Red, Width: 10,Height: 5”。
1 | 输入 |
题解
不知道为什么在main方法里get不管用,在Square里面toString就行
1 | import java.util.Scanner; |
695.岛屿的最大面积
题目描述
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
1 | 输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]] |
题解
此题可以利用深度优先搜索进行解答,外层函数遍历所有位置,寻找可以进行搜索的地方,随后将其存入栈中开始搜索,搜索结束记录本次搜索面积,将其与最大面积进行比较,遍历结束后返回最大面积即可。
1 | class Solution { |
栈的优点就是特别好理解,并且不容易出现栈满的情况,也可以使用递归解答本题
1 | class Solution { |
994.腐烂的橘子
题目描述
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格; - 值
1代表新鲜橘子; - 值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。
1 | 输入:grid = [[2,1,1],[1,1,0],[0,1,1]] |
题解
家人们谁懂,蛮简单一道题卡在了第一个用例上,排查了半天差点把代码重写,最后发现是因为把 = 写成了 ==
与上一题类似,同样遍历整个数组,寻找烂掉的橘子,并从烂橘子开始,遍历四个相邻方向,若有新鲜橘子,则将其腐烂。不同的是,由于每一轮烂橘子都会腐蚀周围橘子,所以使用广度优先搜索,搜索的深度即为所求分钟数。此处可使用列表进行搜索,并使用一个变量cnt记录剩余新鲜橘子数量。先完全遍历数组,将烂橘子放入队列bad中,得到新鲜橘子cnt个,随后一次从bad中取出橘子,遍历其四周,若存在新鲜橘子则将其加入队列,并将cnt-1。
至于如何记录轮次,这里使用了一个二维数组round,初始遍历时将每个烂橘子的round设为1,在随后的循环中每个新鲜橘子的round是前一个烂橘子的round+1。
1 | class Solution { |
24.9
卡码9.奇怪的信
题目描述
有一天, 小明收到一张奇怪的信, 信上要小明计算出给定数各个位上数字为偶数的和。
例如:5548,结果为12,等于 4 + 8 。
小明很苦恼,想请你帮忙解决这个问题。
输入描述
输入数据有多组。每组占一行,只有一个整整数,保证数字在32位整型范围内。
输出描述
对于每组输入数据,输出一行,每组数据下方有一个空行。
题解
很好理解的一道题,但在类型转换上有一些小问题,记录记录,学习学习
本题无非将一行数据作为字符串进行输入,然后再遍历每一位,将偶数位相加,问题是字符转化为int类型并不会一一对应,如若直接int num = s[i],得到的结果会大很多,起初尝试atoi()函数,但会报错(
后来发现……可以直接用s[i]-'0',天才的做法,就此解决
下附源码
1 |
|
努力复健努力复健
卡码11.共同祖先
题目描述
小明发现和小宇有共同祖先!现在小明想知道小宇是他的长辈,晚辈,还是兄弟。
输入描述
输入包含多组测试数据。每组首先输入一个整数N(N<=10),接下来N行,每行输入两个整数a和b,表示a的父亲是b(1<=a,b<=20)。小明的编号为1,小宇的编号为2。
输入数据保证每个人只有一个父亲。
输出描述
对于每组输入,如果小宇是小明的晚辈,则输出“You are my younger”,如果小宇是小明的长辈,则输出“You are my elder”,如果是同辈则输出“You are my brother”。
题解
这道题感觉有些困难的原因出在想复杂了,题目给出的所有用例均在抵达共同祖先时便终止,意味着两人的长辈终止于共同的那一位,所以可以先记录这个亲戚谱系,然后从小明和小宇出发,层层深入,看最终两人分别处于这个树的第几层,通过判断层数大小就可以推断出两人的辈分关系。
1 |
|
但是如果这个谱系图可以无限延伸,并不止于共同祖先呢?
私以为这样会复杂一些
卡码14.句子缩写
题目描述
输出一个词组中每个单词的首字母的大写组合。
输入描述
输入的第一行是一个整数n,表示一共有n组测试数据。(输入只有一个n,没有多组n的输入)
接下来有n行,每组测试数据占一行,每行有一个词组,每个词组由一个或多个单词组成;每组的单词个数不超过10个,每个单词有一个或多个大写或小写字母组成;
单词长度不超过10,由一个或多个空格分隔这些单词。
输出描述
请为每组测试数据输出规定的缩写,每组输出占一行。
题解
这道题不难想,无非获取一整行输入,然后根据空格将句子中的单词切分进string数组,最后遍历数组,将每个单词的首字母转换为大写输出即可;
至于遇到了什么坑呢?
代码运行时,由于测试用例只有一行,打印出的内容为空,但若有多条数据,便总会少一条,怎么回事捏
原因在于输入n后换行,包含一个回车键,若直接getline()读取一整行信息,相当于只读取了回车键,所以需要使用getchar()吸收回车,使得能获取下一行数据
代码如下
1 |
|
卡码17.出栈合法性
题目描述
已知自然数1,2,…,N(1<=N<=100)依次入栈,请问序列C1,C2,…,CN是否为合法的出栈序列。
输入描述
输入包含多组测试数据。
每组测试数据的第一行为整数N(1<=N<=100),当N=0时,输入结束。
第二行为N个正整数,以空格隔开,为出栈序列。
输出描述
对于每组输入,输出结果为一行字符串。
如给出的序列是合法的出栈序列,则输出Yes,否则输出No。
题解
有两种做法,其一是根据栈的特点,对于当前元素 x,若出栈序列合法,需满足 x 之后所有小于 x 的元素为递减的。遍历输出序列,对每个元素进行check,确保其后小于它的所有元素递减。
第二种为模拟栈,若出栈序列合法,则最终栈内元素应为空,由此判断是否合法
先将出栈序列录入数组,然后依次将元素入栈,若栈顶元素与出栈序列当前元素相同,则将其出栈。
1 |
|
卡码18.链表的基本操作
不是很难,但太久没写过链表了,还是有一些小问题,来记录一下
题目描述
本题考察链表的基本操作。温馨提示:本题较为复杂,需要细心多花一些时间。
输入描述
输入数据只有一组,第一行有n+1个整数,第一个整数是这行余下的整数数目n,后面是n个整数。
这一行整数是用来初始化列表的,并且输入的顺序与列表中的顺序相反,也就是说如果列表中是1、2、3那么输入的顺序是3、2、1。
第二行有一个整数m,代表下面还有m行。每行有一个字符串,字符串是“get”,“insert”,“delete”,“show”中的一种。
如果是“get”,代表获得第a个元素。(a从1开始计数)
如果是“delete”,代表删除第a个元素。(a从1开始计数)
如果是“insert”,则其后跟着两个整数a和e,代表在第a个位置前面插入e。(a从1开始计数)
“show”之后没有正数,直接打印链表全部内容。
输出描述
如果获取成功,则输出该元素;
如果删除成功,则输出“delete OK”;
如果获取失败,则输出“get fail”
如果删除失败,则输出“delete fail”
如果插入成功,则输出“insert OK”,否则输出“insert fail”。
如果是“show”,则输出列表中的所有元素,如果列表是空的,则输出“Link list is empty”
注:所有的双引号均不输出。
题解
1 |
|
卡码20.删除重复元素
题目描述
根据一个递增的整数序列构造有序单链表,删除其中的重复元素
输入描述
输入包括多组测试数据,每组测试数据占一行,第一个为大于等于0的整数n,表示该单链表的长度,后面跟着n个整数,表示链表的每一个元素。整数之间用空格隔开
输出描述
针对每组测试数据,输出包括两行,分别是删除前和删除后的链表元素,用空格隔开
如果链表为空,则只输出一行,list is empty
题解
删除的时候有一个小坑,我这里的处理方法逻辑是,循环链表现有元素,如果重复就将其删掉,是一个双重嵌套循环,删除后将指针往后移一个,如果没有重复就直接往后移,问题就出在这里,没有重复的后移并没有套在else的方法体里面,所以——如果重复就会后移两位,于是若最后一个元素需要删除,就会出现指针越界的情况。
放一下长长的代码
1 |
|
 微信
微信 支付宝
支付宝
