
操作系统实验(二) 管道通信
管道
什么是管道
目前在任何一个shell中,都可以使用“|”连接两个命令,shell会将前后两个进程的输入输出用一个管道相连,以便达到进程间通信的目的:
1 | [zorro@zorro-pc pipe]$ ls -l /etc/ | wc -l |
管道本质上就是一个文件,前面的进程以写方式打开文件,后面的进程以读方式打开。这样前面写完后面读,于是就实现了通信。实际上管道的设计也是遵循UNIX的“一切皆文件”设计原则的,它本质上就是一个文件。Linux系统直接把管道实现成了一种文件系统,借助VFS给应用程序提供操作接口。
虽然实现形态上是文件,但是管道本身并不占用磁盘或者其他外部存储的空间。在Linux的实现上,它占用的是内存空间。所以,Linux上的管道就是一个操作方式为文件的内存缓冲区。
管道的分类
Linux中管道分为两种类型
- 匿名管道
- 命名管道
匿名管道最常见的形态就是我们在shell操作中最常用的”|”。它的特点是只能在父子进程中使用,父进程在产生子进程前必须打开一个管道文件,然后fork产生子进程,这样子进程通过拷贝父进程的进程地址空间获得同一个管道文件的描述符,以达到使用同一个管道通信的目的。此时除了父子进程外,没人知道这个管道文件的描述符,所以通过这个管道中的信息无法传递给其他进程。这保证了传输数据的安全性,当然也降低了管道了通用性,于是系统提供了命名管道
由于本次实验主要用到的是匿名管道,所以不再赘述命名管道
匿名管道
管道的创建
管道 pipe 是进程间通信最基本的一种机制,两个进程可以通过管道一个在管道一端向管道发送其输出,给另一进程可以在管道的另一端从管道得到其输入.管道以半双工方式工作,即它的数据流是单方向的.因此使用一个管道一般的规则是读管道数据的进程关闭管道写入端,而写管道进程关闭其读出端.
pipe 系统调用的语法为:
1 |
|
如果对于 pipe_id[1] 写入,调用的是 write(),向 pipe_buffer 里面写入数据;如果对于 pipe_id[0] 的读入,调用的是 read(),也就是从 pipe_buffer 里面读取数据。至此,我们在一个进程内创建了管道,但是尚未实现进程间通信。
要注意,在管道中没有数据的情况下,对管道的读操作会阻塞,直到管道内有数据为止。这就是为什么示例实验中的父子进程之间的执行是交替的。
管道的内核实现
管道实际上就是内核控制的一个内存缓冲区,既然是缓冲区,就有容量上限。我们把管道一次最多可以缓存的数据量大小叫做 PIPESIZE。内核在处理管道数据的时候,底层也要调用类似 read 和 write 这样的方法进行数据拷贝,这种内核操作每次可以操作的数据量也是有限的,一般的操作长度为一个 page,即默认为 4k 字节。我们把每次可以操作的数据量长度叫做 PIPEBUF。POSIX 标准中,对 PIPEBUF 有长度限制,要求其最小长度不得低于 512 字节。PIPEBUF 的作用是,内核在处理管道的时候,如果每次读写操作的数据长度不大于 PIPEBUF 时,保证其操作是原子的。而 PIPESIZE 的影响是,大于其长度的写操作会被阻塞,直到当前管道中的数据被读取为止。
匿名管道通信
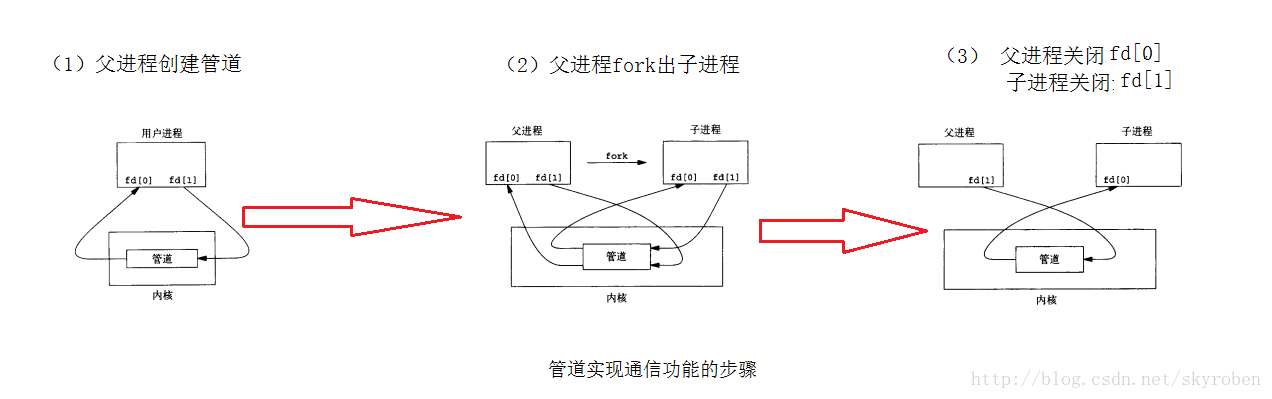
- 父进程创建管道,得到两个⽂件描述符指向管道的两端
- 父进程fork出子进程,⼦进程也有两个⽂件描述符指向同⼀管道
- 禁用父进程的读,禁用子进程的写,即从父进程写入从子进程读出,从而实现了单向管道,避免了混乱。管道是⽤环形队列实现的,数据从写端流⼊从读端流出,这样就实现了进程间通信。
独立实验
与示例实验大体相似,由于只需要存储f(x)、f(y)两个数据,可以只使用一个管道,在两个子进程依次存入x、y,在父进程依次读出。由于是由子进程向父进程发送数据,所以子进程关闭读、父进程关闭写。
1 |
|
 微信
微信 支付宝
支付宝
